PE文件解析(三)
之前讲解了输入表与输入地址表以及他们的工作原理,现在我们开始分析输出表与重定位表
输出表
创建一个DLL时,实际上创建了一组能让exe或其他DLL调用的函数,而PE装载器将根据DLL文件中的输出信息修正正被执行文件中的IAT。通常exe文件中不存在输出表(并不绝对),而大部分DLL文件中则存在输出表
输出表的结构
1 | typedef struct _IMAGE_EXPORT_DIRECTORY { |
现在对一些重要属性做出解释
- TimeDateStamp:输出表的创建时间(GMT时间)
- Name:指向一个ASCII字符串的RVA,即DLL的名字
- Base:一个初始序号值,当通过序号查询输出的函数时,实际数值 = 查询数值 - Base,实际数值即为输出函数地址表(EAT)的索引
- NumberOfFunctions:输出函数地址表中条目的数量
- NumberOfNames:输出函数名称表(ENT)和输出函数序号表中条目的数量
- AddressOfFunctions:输出函数地址表的RVA,是一个RVA数组
- AddressOfNames:输出函数名称表的RVA,也是一个RVA数组,该表会排序
- AddressOfNameOrdinals:输出序号表的RVA,指向输出序号的数组,即一个WORD大小的数组
我们看到结构中提到了3张表,分别是输出函数地址表EAT、输出函数名称表ENT、输出函数序号表,那么他们之间有什么联系呢?且DLL中的函数既可以通过名称导出,也可以通过序号导出,那么两种不同的导出方式,又要如何定位函数的地址呢?
- 函数通过名称导出时,如何建立名称到地址的映射关系就成了关键,而输出函数序号表就是承担中转工作的,我们之前提到这三张表都是数组,假设我们有一个名称A的函数,通过查询ENT表得到其索引为3,那么函数A的序号在函数序号表的索引也是3,我们从序号表中取出该函数的序号,这个序号就是函数A在EAT表中的索引
- 函数通过序号导出时,导出序号 - base = EAT表索引
实例
为了便于理解,假设我们有DLLTest.dll文件,其中定义了4个函数Plus、Sub、Mul和Div,其中Plus、Sub、和Div以函数名导出,并将其导出序号分别设置为1、5、9,而Mul以序号导出,其序号为为7,具体如下
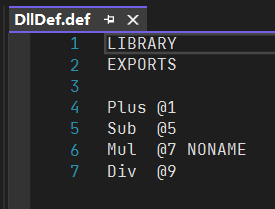
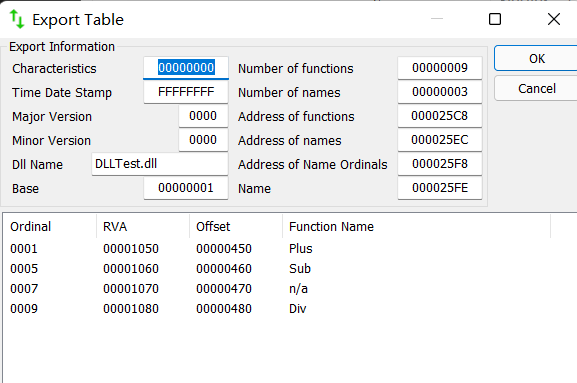
此时我们画一张导出表的示意图来进行细致的解释
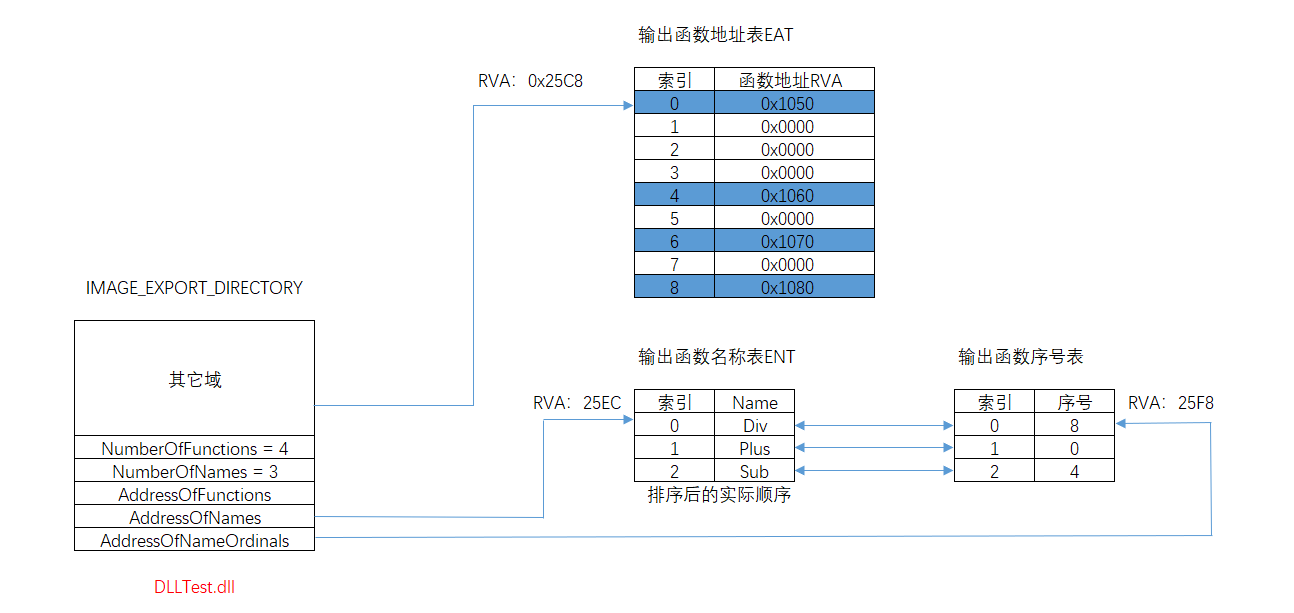
- 对于名称导出方式,以Sub函数为例,我们可以看到它在ENT表中的索引为2,那么我们到序号表中查询索引为2的序号值,其结果为4,这意味着Sub函数的RVA地址存放在EAT表中的索引为4的地方,此时我们再查看EAT表就可以得到Sub函数的RVA为0x1060
- 对于序号导出方式,我们将Mul以序号7将其导出,此时Base = 1,那么Mul的RVA地址在EAT表中的索引就是7 - 1 = 6,通过查EAT表我们得到了Mul的RVA为0x1070
重定位表
首先,为什么会有重定位表,我们都知道在可选映像头中有一个ImageBase属性,这个属性标识了PE文件默认的载入基地址,但是一个exe文件可能同时包含了多个DLL,而这些DLL的ImageBase又都是0x10000000,为了避免冲突现象,我们只能将没抢占到0x10000000这个位置的DLL放入内存中的其他位置,此时就产生了一个问题,DLL中某些数据的地址写的是直接地址(ImageBase + RVA),此时换了一个新的基地址,我们要如何取到正确的取得这些数据呢,这就是重定位表的作用,标识出那些需要修正的位置
重定位表的结构
1 | typedef struct _IMAGE_BASE_RELOCATION { |
- VirtualAddress:重定位数据开始的RVA地址
- SizeOfBlock:重定位块的大小
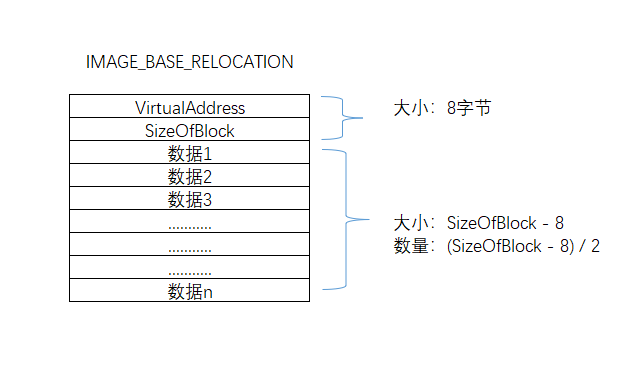
- 首先需要注意的是IMAGE_BASE_RELOCATION并不是孤立的一张表,在结构体后紧跟是一个WORD类型(2字节)的数组,数组长度为(SizeOfBlock - 8)/ 2
- 其次,这些数据是高4位+低12位的结构,其中高4位为修改标记,若其为0011(即十进制的3),则表示该数据需要修改,低12位是一个Offset,需要用重定位表中的VirtualAddress + Offset才是需要修改的数据的RVA;若高4位为0,则不需要修改,作为对齐用
- 每一张重定位表,都会记录一个4KB大小的数据块中需要修改的数据
- 最后,重定位表最终以一个8字节大小的全0结构作为结束的标志
最后,可能有人会有疑问,对于一个寻址能力为32位的操作系统,为什么Offset是一个2个字节大小的结构,内存地址不是需要4字节才能完整表示吗?
这是因为重定位表采用VirtualAddress + Offset表示RVA造成的,我们先来看看这么做的好处,假设我们有一个16KB大小的数据块,其中有1000个需要重定位的数据
- 如果我们采用直接记录RVA的方式,那么只需要一张重定位表,其大小为1000 * 4 = 4000字节(如果需要SizeOfBlock记录大小,则至少为4004字节)
- 如果我们采用VirtualAddress + Offset的方式,那么按实际的重定位表结构,我们将会有4张重定位表(每个重定位表只记录4KB大小的数据块),假设这1000个数据均匀分布在这4张表中,那么每张重定位表的大小为 8 + 250 * 2 = 508字节,那么4张重定位表总共2032字节,我们可以发现这样的设计大大缩小了重定位表的大小
在理解了这样设计的好处之后,现在我们来回答,为什么Offset只需要两字节
从原理的角度:一张重定位表记录一个4BK大小的数据块(即0x0000 ~ 0x0FFF),也就是说,我们的Offset只要能表示这个范围内的地址即可,因此Offset只需要12位即可表示(即重定位表中数据的低12位),处于对齐和功能性,我们将其设计为16位,即2字节,那么高4位就用来记录是否需要修改这一信息,所以VirtualAddress大小为4字节,可以记录任意数据块的在内存中的起始地址RVA,而Offset只需要2字节就可表示块内的任意Offset
实例
还是以之前DLLTest.dll为例,我们在PE Tools中可以看到,该文件共有两张重定位表,标识了不同区块中需要修正的数据,其中.text中共有140个可能需要重定位的数据,而.data中有16个
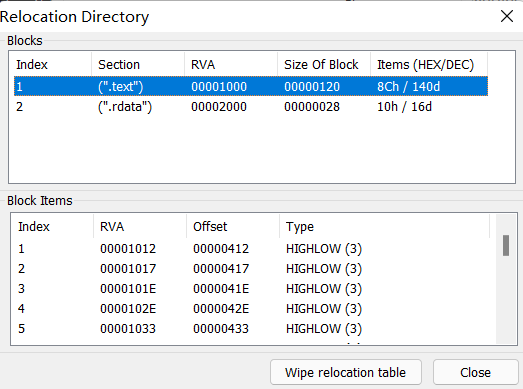
我们以.text中的第一个、第三个需要修改的数据为例,首先分析下他们的RVA 0x1012和0x101E是怎么得到的,我们在16进制编辑器中找到重定位表,红框圈中的即为第一项数据0x3012和第三项数据0x301E,我们将其转换为二进制分别为0011 0000 0001 0010和0011 0000 0001 1110,可以发现他们的高4位都为0011,即需要修改,那么他们的低12位为Offset,分别是0x12和0x1E,那么需要修改的数据的RVA分别为VirtualAddress + Offset,即0x1012和0x101E

此时DLLTest.dll的ImageBase为0x10000000,我们用另一个程序调用DLLTest.dll,并用x64Dbg打开该程序,找到0x10001012处,可以发现其中一个是Push指令,而另一个是call指令(因为Push指令的操作码为0x68,需要占用一个字节,所以指令开始的地址是0x0x10001011,而0x10001012才是实际需要修改的数据的起始地址,call指令同理),那么当DLLTest.dll发生重定位时,这两个部分的数据就需要修改,此时记下他们:①0x100020A4;②0x10002030

现在我们让DLL不从ImageBase载入,但不修改ImageBase中的值,我们在VS中将随机基址的打开,然后重新编译我们的DLL和调用该DLL的程序,现在虽然DLL的ImageBase还是0x10000000,但实际载入内存时DLL并不会从ImageBase载入
我们在x64Dbg中重新定位,可以发现此时我们的DLL已经被放到了内存中的其他位置,且载入的基地址为0x78590000,此时我们看到RVA为0x1012处的数据被改成了0x785920A4,而RVA为0x101E处的数据被改为了0x78592030

我们不难看出这两个值是如何计算得到的
- 0x785920A4 = 0x100020A4 - 默认基地址0x10000000 + 新基地址0x78590000
- 0x78592030 = 0x10002030 - 默认基地址0x10000000 + 新基地址0x78590000